[Stanford CS229] Lecture 4 강의 정리
by 구설구설Perceptron
Lecture 3에서의 ~Sigmoid Function~은 ($ -\infty $, $\infty$)를 $ [0, 1] $로 매핑하는 부드러운 곡선 형태를 갖고 있다.
~Perceptron~은 Sigmoid Function과 달리 곡선 형태가 아닌 보다 극단적인 형태를 가지고 있다.


Perceptron과 Sigmoid Function의 차이
- 부드러운 곡선 대신 hard threshold를 사용한다.
- $g(0) = 0.5. $
- \( z \to -\infty \)일 때, \( g(z) \to 0 \).
- \( z \to \infty \)일 때, \( g(z) \to 1 \).
Perceptron의 Update Rule
\[
\Theta_j = \Theta_j + \alpha \cdot (y_i - h_\Theta(x_i)) \cdot x_{ij}
\]
- $ \alpha $: Learning rate
- $ y_i $: 실제 값 (0 또는 1)
- $ h_\Theta(x_i) $: 예측 값
- $ x_{ij} $: j번째 파리미터의 데이터 값
Update Rule의 특징
$y_i - h_\Theta(x_i)$은 다음 값을 갖는다:
- $0$: 예측이 맞았을 경우
- $1$: 실제 값이 1이고 예측 값이 0으로 틀린 경우
- $-1$: 실제 값이 0이고 예측 값이 1으로 틀린 경우
기하학적 이해

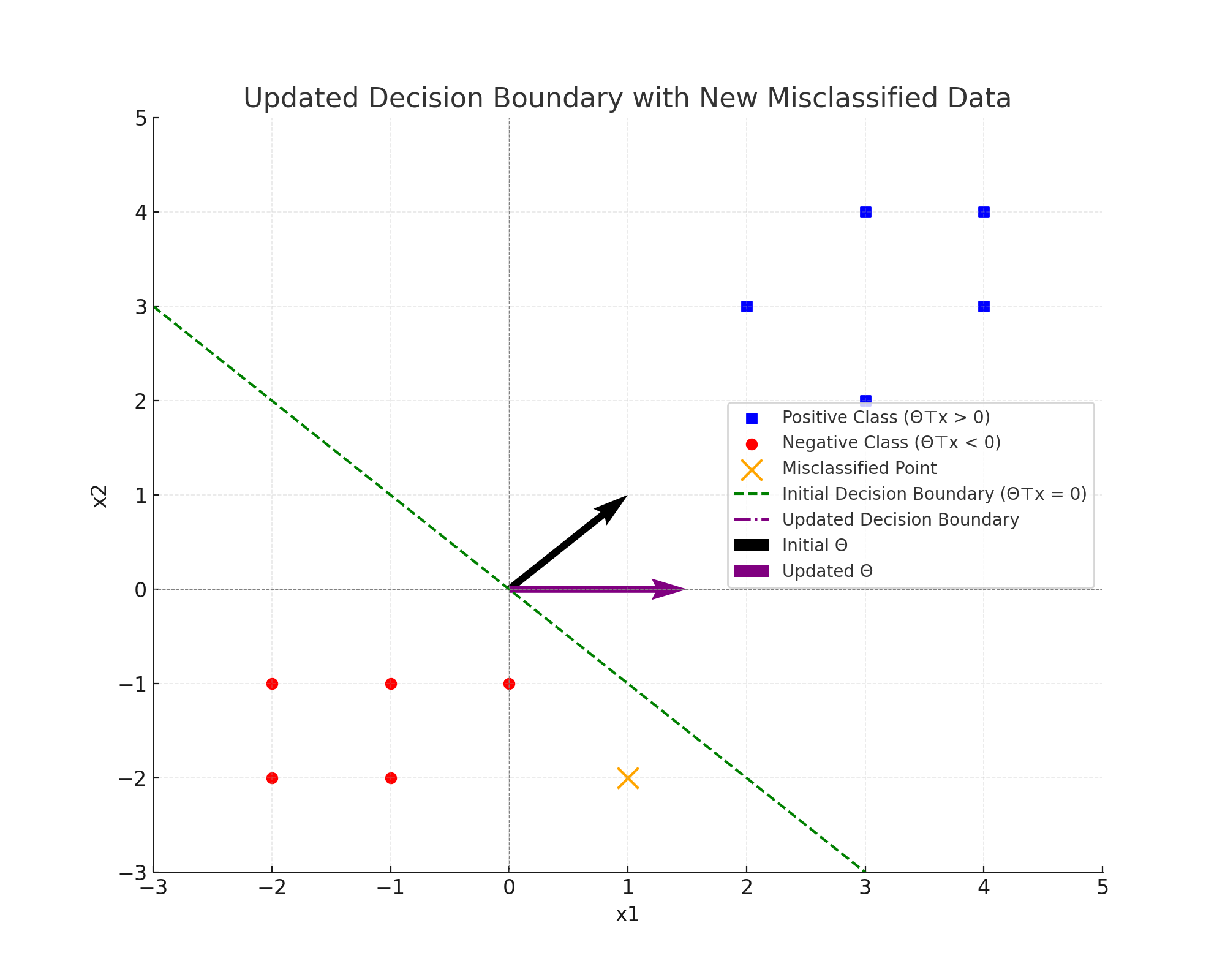
- $ \Theta^\top x = 0 $: 경계선을 의미.
- $ \Theta^\top x > 0: $: 1로 예측됨
- $ \Theta^\top x < 0: $: 0으로 예측됨
잘못 예측한 값이 있는 경우
- $y = 1$: $\theta$를 조정하여 경계선이 $x$에 더 가깝게 조정한다.
- $y = 0$: $\theta$를 조정하여 경계선이 $x$에서 더 멀어지도록 조정한다.
Exponential Family
~Exponential Families~는 확률 분포의 한 종류로, GLMs(Generalized Linear Models)과 밀접한 연관이 있다.
\[
p(y; \eta) = b(y) \exp\left(\eta^\top T(y) - A(\eta)\right)
\]
$ y $: 데이터
$ \eta $: Natural parameter
$ T(y) $: Sufficient statistcs, 경우에 따라 $y$와 동일하게 사용됨.
$ b(y) $: Base measure, $y$로만 이루어진 함수.
$ A(\eta) $: Log-partition function, 적분 결과가 1이 되도록 정규화
Exponential Family의 예시
- 베르누이 분포
- PDF: $$ p(y; \phi) = \phi^y (1 - \phi)^{1-y} $$
- $\phi$: 성공 확률
- $ y \in \{0, 1\} $
- Exponential Family의 형태: $$ p(y; \phi) = \exp\left(y \log\frac{\phi}{1 - \phi} + \log(1 - \phi)\right) $$
- $ \eta = \log\frac{\phi}{1 - \phi} $
- $ T(y) = y$
- $ b(y) $: $1$
- $ A(\eta)=-\log(1-\phi)=-\log\left(1-\frac{1}{1+e^{-\eta}}\right)=\log\left(1+e^{\eta}\right) $
- PDF: $$ p(y; \phi) = \phi^y (1 - \phi)^{1-y} $$
- 가우시안 분포
- PDF: $$ p(y; \mu) = \frac{1}{\sqrt{2\pi}} \exp\left(-\frac{(y - \mu)^2}{2}\right) $$
- 분산은 1로 가정.
- Exponential Family의 형태: $$ p(y; \mu) = \exp\left(-\frac{y^2}{2} + \mu y - \frac{\mu^2}{2} - \log\sqrt{2\pi}\right) $$
- $ \eta = \mu $
- $ T(y) = y$
- $ b(y) = 1$
- $ A(\eta) = \frac{\mu^2}{2}=\frac{\eta^2}{2} $
- PDF: $$ p(y; \mu) = \frac{1}{\sqrt{2\pi}} \exp\left(-\frac{(y - \mu)^2}{2}\right) $$
Exponential Family의 특징
- 최적화 용이성
- Exponential Family를 사용한 MLE는 오목 함수를 가져서 전역 최댓값을 보장한다.
- Negative Log-Likelihood는 볼록 함수여서 전역 최솟값을 보장한다.
- 평균과 분산
- 평균: $$ E[y] = \frac{\partial A(\eta)}{\partial \eta} $$
- 분산: $$ \text{Var}(y) = \frac{\partial^2 A(\eta)}{\partial \eta^2} $$
Generalized Linear Models (GLMs)
~GLM~은 적절한 Exponential Family 분포를 선택하여 다양한 데이터 타입에 유연한 모델링을 제공한다.
데이터 타입에 따른 모델 선택
- 가우시안(Gaussian): 실수형 데이터(회귀)에 사용된다.
- 베르누이(Bernoulli): 이진 데이터(분류)에 사용된다.
- 푸아송(Poisson): 카운트 데이터에 사용된다.
- 감마/지수(Gamma/Exponential): 양의 실수 값(예: 사건 발생 시간)에 사용된다.
수식 관계
Natural paramter $\eta$는 $ \eta = \Theta^\top x $로 표현된다.
- $ \Theta $: 모델의 파라미터 값
- $ x $: 입력 데이터
테스트 과정에서 Exponential Family 분포의 평균이 예측 결과로 사용된다.
$$ E[y \mid x] = h_\Theta(x) $$
- $ h_\Theta(x) $: 분포의 평균으로 예측 함수의 역할을 한다.
GLM 트레이닝
MLE와 경사 상승법으로 $ \theta $를 학습한다:
$$ \text{Objective} = \Theta_{\text{max}} \prod_{i=1}^{N} P(y_i \mid x_i; \Theta) $$
업데이트 규칙은 다음과 같다:
$$ \Theta_j = \Theta_j + \alpha \cdot \sum_i (y_i - h_\Theta(x_i)) x_{ij} $$
특징
- Exponential Family 분포는 공통된 구조를 가지기 때문에, 데이터의 형태와 상관없이 모든 분포에 대해 경사를 일관된 방식으로 구할 수 있다.
- 분포에 의해 결정된 $ h_\Theta(x_i) $에 따라 동일한 업데이트 규칙을 적용할 수 있다.
- 가우시안(Gaussian): $ h_\Theta(x) = \Theta^\top x $
- 베르누이(Bernoulli): $ h_\Theta(x) = \frac{1}{1 + e^{-\Theta^\top x}} $
- 푸아송(Poisson): $ h_\Theta(x) = e^{\Theta^\top x} $
Softmax Regression
~Softmax Regression~은 Logistic Regression을 다중 클래스 분류로 확장한 모델이다.
입출력 값
- 입력 값: $ x \in \mathbb{R}^n $, 데이터 벡터
- 출력 값: $ y \in \{0, 1\}^k $, 예측 값에 해당하는 종만 1로 표현된다.
- 예시: $ k = 3 $ (원, 사각형, 삼각형)
- 원: $ [1, 0, 0] $
- 사각형: $
[0, 1, 0]
$ - 삼각형: $
[0, 0, 1]
$
파라미터
각 종 $i$은 자신만의 파라미터 $ \Theta_i \in \mathbb{R}^n $를 갖는다.
따라서 전체 파라미터는 $ \Theta \in \mathbb{R}^{n \times k} $ 행렬으로 표현할 수 있다.
과정

입력 값에 대하여 모델이 각 종에 점수를 계산한다.
$$ z_i = \Theta_i^\top x, \forall i \in \{1, \ldots, k\} $$

Softmax Function을 사용하여 수를 확률로 변환한다.
\[
P(y = i \mid x) = \frac{\exp(\Theta_i^\top x)}{\sum_{j=1}^k \exp(\Theta_j^\top x)}
\]
- $ P(y = i \mid x) $: $x$가 종 $i$에 속하는지의 확률

최종 결과를 만든다.
Cross Entropy
최적화를 위해 ~Cross Entropy~ Loss를 사용한다:
$$ \text{Loss} = -\log \hat{p}(y = i \mid x) $$
전체 데이터셋의 Loss를 구한 뒤 경사하강법으로 최적화한다.
'CS > AI & ML' 카테고리의 다른 글
| [Stanford CS229] Lecture 3 강의 정리 (0) | 2024.12.03 |
|---|
블로그의 정보
공부중임
구설구설