[Stanford CS229] Lecture 3 강의 정리
by 구설구설
Parametric vs. Non-Parametric Learning Algorithms
Parametric Learning Algorithms
- 개수가 고정된 파라미터 세트~를 데이터에 맞춘다.
- 파라미터들은 학습 이후 고정된다.
- 파라미터 ~θ~만 예측을 위해 사용되므로, 학습 데이터는 학습 이후 없어도 된다.
- 모델의 크기가 학습 데이터의 크기와 관련이 없다.
- 예시: ~선형 회귀~
- 파라미터 (θ_0,θ_1,…,θ_n)는 ~cost function~을 최소화하기 위해 최적화된다.
- 모델은 $h_\theta(x) = \theta^T x$ 으로 표현된다.
Non-Parametric Learning Algorithms
- 파라미터의 수가 고정되어 있지 않다.
- 학습 데이터가 커질수록 모델의 복잡성이 커지고, 계산 비용이 늘어난다.
- 학습 데이터를 메모리에 저장하고 있어야 한다.
- 예측은 입력 값의 이웃한 데이터에 의존한다.
Locally Weighted Regression (LWR)
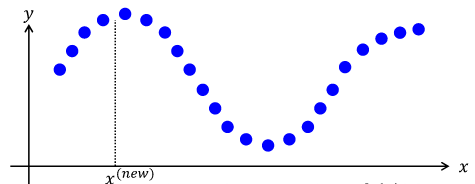
예를 들어 위와 같은 데이터들이 있다고 가정한다면,
~선형 회귀~는 비용 함수가 최소화되도록 θ를 맞춘 후 $ \theta^T x $를 통해 예측을 수행한다.

그러나 선형 회귀를 수행한 결과가 위 그림과 같다면, 예측이 정확하다고 말할 수 없을 것이다.
따라서 하나의 전역적인 모델이 아닌 예측하고자 하는 $ x $의 근처의 데이터에 집중하여 예측을 수행하는 것을 ~Locally Weighted Regression~, ~LWR~라고 한다.

LWR의 과정
- $ x $가 예측하고자 하는 값의 인풋으로 주어진다.
- 각 학습 데이터($ x_i, y_i $)에 $ x $와의 거리에 따른 가중치를 부여한다.
- weighting function의 특징
- $ x $에 가까울수록: $ (\lvert x_i - x \rvert \text{ small}) \rightarrow w_i \approx 1. $
- $ x $에 멀수록: $ (\lvert x_i - x \rvert \text{ large}) \rightarrow w_i \approx 0. $
- 예시: ~Gaussian Function~, $ w_i = e^{- \frac{(x_i - x)^2}{2\tau^2}} $
- weighting function의 특징
- 비용 함수 $ J(\theta) = \sum_{i=1}^m w_i \cdot \left( h_\theta(x_i) - y_i \right)^2 $을 최소화 하도록 모델을 맞춘다.
- 비용 함수는 기존의 비용 함수에 가중치를 곱한 형태이다.
- 예측을 수행한다.
- 매 예측마다 위 단계를 반복한다.
Bandwidth ($ \tau $)

- Gaussian weight function의 폭을 결정하는 파라미터이다.
- 예측에 사용할 이웃하는 데이터를 결정하는데 영향을 준다.
- 큰 $ \tau $: 더 많은 데이터를 고려 → 고른 예측. 그러나 ~Underfitting~의 가능성
- 작은 $ \tau $: 더 적은 데이터를 고려 → 예측의 유연성 상승, 그러나 ~Overfitting~의 가능성
선형 회귀의 확률적 해석
선형 회귀의 확률적 모델
$ y_i = \theta^T x_i + \epsilon_i $
- $ y_i $: 실제 출력값 (예: 집값)
- $ x_i $: 입력 값 (예: 집 면적, 방의 수)
- $ \epsilon_i $: 노이즈 또는 모델화 되지 않는 영향들 (예: 집 주인의 기분, 날씨 등)
- $ \epsilon_i \sim N(0, \sigma^2) $: 평균이 0이고 분산이 $ \sigma^2 $이다.
- ~중심 극한 정리 (CLT)~: 많은 독립적이고 작은 노이즈가 합쳐지면 Gaussian 분포를 따른다.
- $ \epsilon_i $은 독립적으로 동일하게 분포되어 있다고 가정한다.(IID)
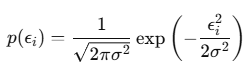
Likelihood와 Probability
~Likelihood(우도)~:
- 데이터를 고정된 값으로 보고, 파라미터를 변수로서 조정
~Probability(확률)~:
- 고정된 파라미터에서 데이터를 관찰할 확률을 나타냄
따라서 데이터의 Probability, 파라미터의 Likelihood로 표현해야 한다.
Likelihood & Log-Likelihood Function
~Likelihood Function~:
$ L(\theta) = P(\text{data} \mid \theta) = \prod_{i=1}^m P(y_i \mid x_i; \theta) $
- $ m $: 학습 데이터의 개수
- $ P(y_i \mid x_i; \theta) $: $ x_i $와 $\theta$에 기반한 $y_i$의 확률
~Log-Likelihood Function~:
$ \ell(\theta) = \log L(\theta) = \sum_{i=1}^m \log P(y_i \mid x_i; \theta) $
- log를 취해서 Likelihood의 최댓값을 구하는 것을 덧셈으로 바꾸어 더 쉽게 만들 수 있다.
Maximum Likelihood Estimation (MLE)
Gaussian 분포를 따르는 $ P(y_i \mid x_i; \theta) $를 통해 Log-Likelihood Function을 단순화할 수 있다.

앞의 항은 상수이기에, 뒤의 항만 최소화 한다면 likelihood를 최대화할 수 있다.
따라서 Cost Function을 최소화하는 것은 Gaussian 분포의 노이즈라는 가정 하에서 MLE를 수행하는 것과 동일하다.
Logistic Regression
종양의 악성 여부와 같은 $ H_\theta(x) \in [0, 1] $인 binary classification의 경우에 linear regression을 수행하는 것은 적합하지 않다.
classification 알고리즘 중 가장 많이 사용되는 것은 logistic regression이다.
logistic regression은 $ H_\theta(x) $가 0과 1 사이에 있다는 것을 전제로 한다.
Sigmoid Function
$$ g(z) = \frac{1} {1 + e^{-z}} $$
sigmoid function은 다음과 같으며, 아래의 특징을 가진다.
$ g(z) \approx 0 \text{ for } z \to -\infty, \quad g(0) = 0.5, \quad g(z) \approx 1 \text{ for } z \to +\infty. $
따라서 sigmoid function을 사용하여 logistic regression을 사용하기 위한 전제를 항상 만족시킬 수 있다.
Probability Assumptions
binary classification에 대하여:
- $ P(y = 1 \mid x; \theta) = h_\theta(x) $
- $ P(y = 0 \mid x; \theta) = 1 - h_\theta(x) $
라고 말할 수 있으며, 위 두 식을 하나로 합쳐
$ P(y \mid x; \theta) = h_\theta(x)^y (1 - h_\theta(x))^{1-y} $
으로 y가 1이면 $ h_\theta(x) $, y가 0이면 $ 1 - h_\theta(x) $가 된다.
Logistic Regression의 MLE
logistic regression의 likelihood function은 다음과 같다.
$ L(\theta) = \prod_{i=1}^m h_\theta(x^{(i)})^{y^{(i)}} (1 - h_\theta(x^{(i)}))^{1 - y^{(i)}} $
계산을 단순화하기 위해 linear regression과 마찬가지로 log를 붙이면
$ \ell(\theta) = \sum_{i=1}^m \left[ y^{(i)} \log h_\theta(x^{(i)}) + (1 - y^{(i)}) \log (1 - h_\theta(x^{(i)})) \right] $가 된다.
Logistic Regression의 Gradient Ascent
$ \ell(\theta) $를 최대화하기 위해 ~gradient ascent~를 사용한다.
- linear regression과 다르게 cost function을 최소화하는 것이 아닌 likelihood function을 최대화할 것이기 때문이다.
- logistic regression은 오목함수의 log-likelihood fucntion을 가져 global maximum을 가진다.
$ \theta_j := \theta_j + \alpha \frac {\partial \ell(\theta)}{\partial \theta_j} $
위 식에서 $ \frac{\partial \ell(\theta)}{\partial \theta_j} $을 계산하면 아래와 같다.
\[
\frac{\partial \ell^{(i)}}{\partial \theta} =
\left( \frac{h_\theta}{y^{(i)}} - \frac{1 - h_\theta}{1 - y^{(i)}} \right) \cdot h_\theta \cdot (1 - h_\theta) \cdot x^{(i)}
=
\frac{\partial \ell^{(i)}}{\partial h_\theta} \cdot
\frac{\partial h_\theta}{\partial z^{(i)}} \cdot
\frac{\partial z^{(i)}}{\partial \theta} =
y^{(i)} - h_\theta(x^{(i)})
\]
sigmoid function 미분 과정에 대해서는 아래 링크를 참고한다.
Sigmoid 함수 미분 정리
Deep Learning을 이론적으로 접근할 때 가장 먼저 접하는 수식이 sigmoid입니다. sigmoid 함수의 미분 절차를 정리합니다.
taewan.kim
sigmoid function을 사용한 logistic regression의 log-likelihood는 오목한 함수이므로, 항상 global maximum을 보정한다.
gradient ascent를 다시 한번 정리하자면,
$ \theta_j := \theta_j + \alpha \sum_{i=1}^m \left[ y^{(i)} - h_\theta(x^{(i)}) \right] x_j^{(i)} $
을 수렴할 때까지 반복하는 것과 같다.
Newton's Method
gradient ascent와 gradient descent를 사용하기 위해서는 작은 step들을 거치면서 천천히 maximum/minimum으로 수렴해야 했다.
이런 step들은 최악의 경우 너무 많이 필요할 수 있는데, ~Newton's Method~는 훨씬 더 빠르게 수렴할 수 있도록 해준다.
Key Idea
Newton's method는 $ f(\theta) = 0 $를 만족시키는 $ \theta $를 찾는 방법이다.
$ L(\theta) $를 최대화하려 한다 가정한다면, $ L'(\theta) = 0 $인 지점에서 최댓값을 가지게 된다.
따라서 Newton's method를 사용해 $ L'(\theta) = 0 $를 인 지점을 찾아 $ L(\theta) $이 최대인 지점을 찾겠다는 아이디어이다.
방법

- 초기 추정값 $ \theta_0 $로 시작한다.
- 함수 $ f(\theta) $를 $ \theta_t $에서 접선으로 근사한다.
- 이 접선이 x축과 교차하는 지점을 구한다.
- $ \theta $를 이 교차 지점으로 업데이트한다.
- 수렴할 때까지 이 과정을 반복한다.
수식으로 표현하면 $ \theta^{(t+1)} := \theta^{(t)} - \frac{f(\theta^{(t)})}{f^{\prime}(\theta^{(t)})} $이다.
특징
Newton's method는 ~quadratic convergence~라는 특징을 가진다.
예를 들어 어떤 회차의 에러가 0.01일 때, 그 다음 회차에서는 에러가 0.00001, 그 다다음 회차에서는 0.000000001이 될 수 있다는 것이다.
이런 특징 때문에 일반적인 batch gradient보다 훨씬 빠르게 수렴할 수 있다.
$ \theta $가 벡터인 경우
만약 파라미터가 여러 개여서 $ \theta $가 벡터인 경우에는 위에서 언급된 수식도 변경 되어야 한다.
$$ \theta^{(t+1)} := \theta^{(t)} - H^{-1} \nabla_{\theta} \mathcal{l}(\theta) $$
$ H $는 Hessian 행렬이다.
헤세 행렬(Hessian Matrix)의 기하학적 의미 - 공돌이의 수학정리노트 (Angelo's Math Notes)
angeloyeo.github.io
Newton's method는 각 회차마다 이런 Hessian 행렬을 계산해야 하는데,
이는 ~O(n^3)~의 시간복잡도를 가진다.
따라서 파라미터가 많아 고차원 백터 연산을 수행해야 하는 경우에는 Newton's method 사용을 피하는 것이 좋다.
'CS > AI & ML' 카테고리의 다른 글
| [Stanford CS229] Lecture 4 강의 정리 (0) | 2024.12.14 |
|---|
블로그의 정보
공부중임
구설구설