[CA] Loop-Level Parellelism & Instruction Scheduling
by 구설구설
위 예제에서 부동 소수점 연산 fadd.d는 매 반복마다 8 사이클이 필요하다.

addi x1, x1, -8은 아무것에도 의존하고 있지 않기 때문에,
위의 stall로 인한 빈칸에 끼워넣어도 아무런 문제가 되지 않는다.
따라서, 매 반복마다 7 사이클이 필요하다.
Loop Unrolling
기존에 1000번 반복하던 예제를,
이제는 한 번에 4개를 계산하고 총 250번 반복하는 방식으로 변경.
이렇게 반복을 풀어내는 것을 Loop Unrolling이라고 한다.

기존에 반복 1회마다 존재하던 addi와 bne를 줄일 수 있다.
4개의 element를 처리하는데 총 26 사이클이 필요하다.
(fadd.d와 fld로 인한 stall 3개)
6.5로 사이클 수가 감소한다.
레지스터가 기존의 방법보다 많이 필요하다.
이를 Register Pressure가 증가 했다고 한다.
Pipeline Schedule
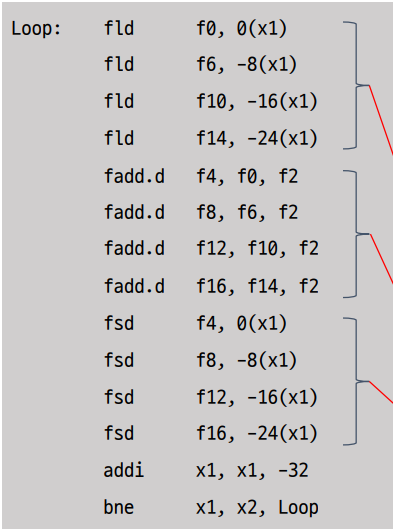
명령어의 순서를 위와 같이 바꾸어도 문제가 없다.
이렇게 되면 stall을 완전히 없앨 수 있다.
Strip Mining
루프의 상한을 보통 알지 못한다.
- 반복 횟수 = n
- 목표: 루프 본체를 번 복사
- 루프 쌍 생성:
- 첫 번째 루프는 𝑛mod𝑘 번 실행
- 두 번째 루프는 번 실행
- 큰 값의 에 대해 대부분의 실행 시간은 언롤된 루프 본체에서 소비된다.
Software Pipelining


기존의 서로 다른 반복의 유의미한 부분이 한 반복 안에 들어 있어 stall 없이 명령어를 실행 할 수 있다.
Loop Unrolling vs. Software Pipelining


- 성능: 상황에 따라 다르다.
- 코드 사이즈: 루프 언롤링은 코드 사이즈가 커지는 반면, 소프트웨어 파이프라이닝은 상대적으로 작다.
- 레지스터 압력: 루프 언롤링은 레지스터 사용량이 증가하지만, 소프트웨어 파이프라이닝은 레지스터 사용량이 적다.
VLIW processor
여러 개의 명령어를 하나의 명령어로 묶어서 동시에 실행할 수 있는 프로세서
여러 명령어를 동시에 실행하기 위해서는 연산을 위한 유닛이 여러 개 필요하다.
컴파일러는 코드를 읽고 최대한 많은 명령어를 병렬로 묶을 필요가 있다.

5개의 하드웨어로 구성된 VLIW 프로세서.
한 번의 실행으로 9 사이클 동안 7개를 처리할 수 있다.
CPI는 1.29(9/7).
VLIW 프로세서의 단점
여러 개의 유닛을 가지기 위한 실리콘 Area, 실행 시 들어가는 전력 소모, 런타임 복잡성.
코드 크기가 커지며, 컴파일러가 유닛들의 빈자리를 채우기 위한 부담이 크다.
Lockstep operation이 있기 때문에 유닛들이 따로따로 작동할 수 없다.
따라서 한 유닛에 stall이 존재하면 다른 유닛들도 기다려야 한다.
이로 인해 성능의 이점을 잃을 수 있다.
비슷한 연산을 많은 데이터에 대해 반복적으로 수행하는 경우에 적합하다. (DSP 등)
'CS > CA' 카테고리의 다른 글
| [CA] Scoreboarding (0) | 2024.05.30 |
|---|---|
| [CA] ILP - Introduction (0) | 2024.05.24 |
블로그의 정보
공부중임
구설구설